Research
| Home |
| Research |
| Publications |
| CV |
| Teaching |
| Software |
![]()
![]()
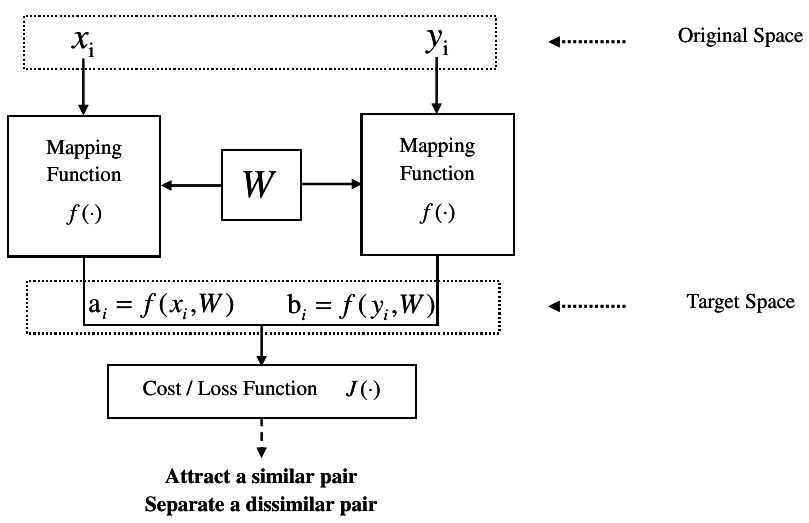
Similarity metric learning
Person reidentification
We proposed several approaches for similarity metric learning with pedestrian images for person re-identification across different camera views. In particular, we introduced some specific Siamese Neural Network (SNN) architectures and appropriate learning strategies that incorporate semantic prior knowledge by a combination of supervised and weakly supervised learning algorithms. For example, we used semantic pedestrian attributes (clothing type and colour, hair style, carried bags etc.), the human body orientation and the surrounding context (i.e. accompanying persons) to improve the re-identification performance. We also proposed a new SNN-based similarity metric learning algorithm that directly optimises the ranking performance by a particular objective function defined on lists of examples and a novel triplet-based rank learning strategy.
![]()
Papers: IVC2013, ICIP2018, ACIVS2018a, ACIVS2018b, VISAPP2018, AVSS2017, ORASIS2017
Face verification
We developed a similarity metric learning algorithm called Triangular Similarity Metric Learning (TSML) that is using an SNN model and pairwise training with a new objective function that improves the convergence behaviour during learning and improved the state of the art in face verification on public benchmarks such as "Labelled Faces in the Wild"" (LFW).
 |
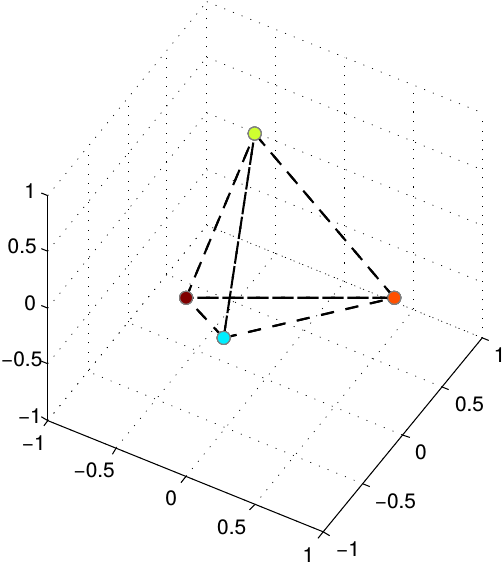 |
Papers: TCYB3, FG2018a, FG2018b, ICASSP2018a, MTA2018a
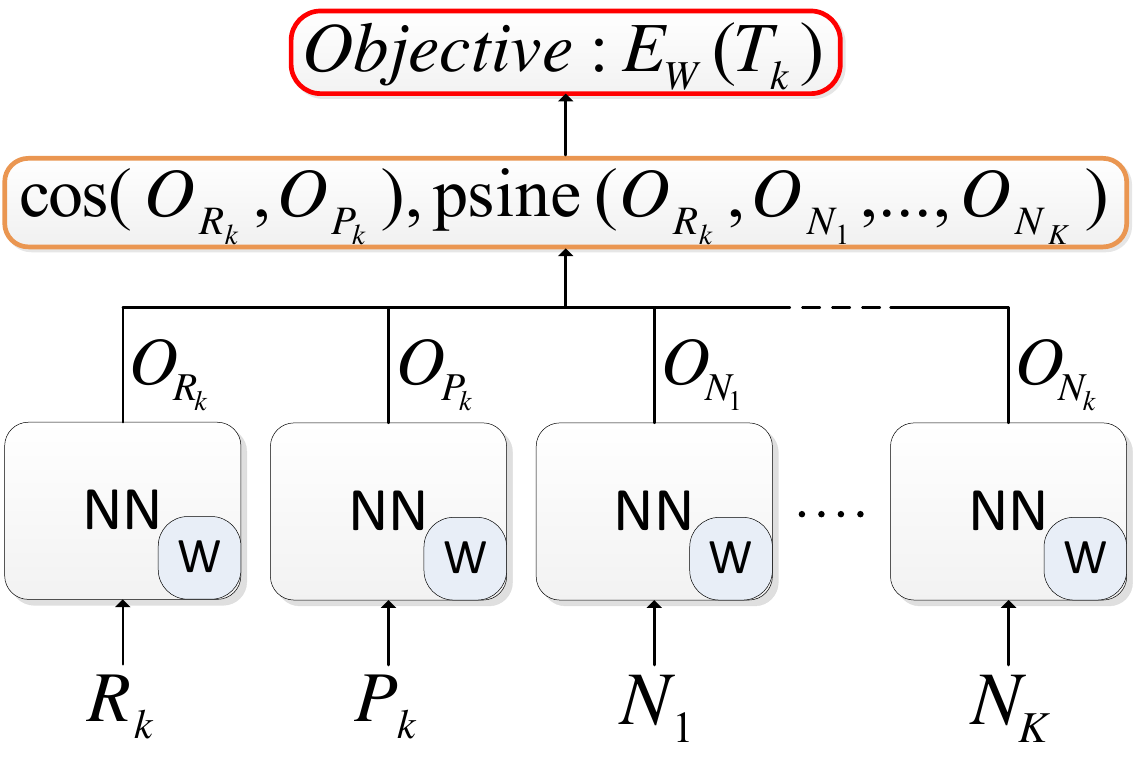
Gesture and action recognition
Our work on SNNs for gesture and action recognition with inertial sensor data proposes several new objective functions the improve the similarity learning convergence as well as a subsequent classification stage. We notably introduced a class-balanced Siamese training algorithm that, at each training iteration, incorporates tuples of negative pairs and an objective function based on the polar sine function. We also developped a method to improve on the performance of correctly rejecting unknown classes in a classification setting.
 |
 |
Papers: NEUROCOMP2017, ICANN2016, FG2018
Object and face tracking
Pixeltrack
A very fast adaptive algorithm for tracking deformable generic objects online. |
 |
 |
 |
 |
Find more information on the PixelTrack web page.
Exploiting contextual information
Several approaches for including context information in on-line visual object tracking have been proposed. For example, we introduced a method, to learn on-line a discriminative classifier by stochastically sampling negative image examples from moving background regions that are likely to distract the tracking of the given object.
Further, we presented various methods to combine several independent tracking algorithms depending on the scene context. This is achieved by a trained scene context classifier and an appropriate tracker selection and combination strategy.
 |
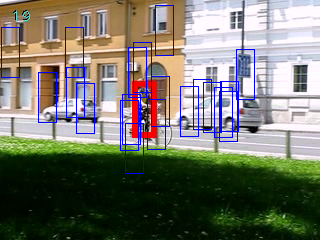 |
Papers: TCSVT2016, ECCV2015 (WS), BMVC2015, VISAPP2015
Visual Focus Of Attention estimation
We developed a method to learn online, unsupervised, and in real-time the Visual Focus Of Attention (VFOA) of people in video-conferencing or meeting room scenarios. The method uses a specific type of online clustering (similar to sequential k-means) to group face patch appearances coming from a face tracking algorithm. By learning these appearance clusters from low-level features we can directly estimate the VFOA without the intermediate step of head pose estimation. Further, the method does not need any prior knowledge about the room configuration or persons in the room. Our experimental results on 110 minutes of annotated data from different sources show that this approach can outperform a classical supervised method based on head orientation estimation and Gaussian Mixture Models.Evaluation data: TA2 database (fullHD resolution reduced to 960x540), IHPD, PETS 2003,
Annotation: VFOA annotation (Please cite our paper (AVSS2013) if you use our data or annotation (bibtex).)
Online multi-modal speaker detection and tracking
In the TA2 project, we developed a real-time system for multi-modal speaker detection and tracking, in a living room environment where the camera and microphone array are not colocated. The system is able to detect for a varying number of persons, the position of faces, where each person is looking at (i.e. the visual focus of attention), when someone is speaking, who is speaking, and map the IDs to the respective visually tracked faces. Moreover, a keyword spotting algorithm has been integrated. The purpose of this processing is to automatically cut to interesting portions inside the video picture (i.e. to automatically edit the video) in real-time, based on these audio-visual cues.Demo: Controlled environment (9.4MB)
Papers: ICME2011, MMM2012, AM2013
Evaluation data: TA2 database
Online multiple face tracking
Also in the context of the TA2 project, we proposed an efficient particle filter-based online multi-face tracker with MCMC sampling. It is able to deal reliably with false face detections and missing detections over longer periods of time. The proposed method is based on a probabilistic framework taking into account longer-term observations, and not only reasoning on a frame-by-frame basis, as it is commonly done.
![]()
Demos: TA2 video (12MB)
Evaluation data: TA2 database
Effective multi-cue object tracking
Fusing multiple cues (like colour, texture) in a tracking framework is not a trivial task. We developed an efficient sampling technique, called Dynamic Partitioned Sampling (DPS), that is able to fuse several cues in a principled way, using a dynamic estimation of the reliability of each cue at each point in time. We evaluated this method in a face tracking application on several videos.In the following example, we use colour (blue rectangle), texture (red rectangle), and shape (green ellipse) cues to track a head. During the video, the estimated reliability of the different cues is dynamically adapted, e.g. when the girl turns around or when her head gets occluded.
 |
 |
 |
 |
 |
 |
| Demos: | girl (1.8MB) (left: no dynamic fusion, middle: partitioned sampling (fixed order), right: Dynamic Partitioned Sampling) |
| twopeople (0.5MB) |
Papers: BMVC2009
Face image processing
We presented several novel approaches to facial image processing based on convolutional neural networks (CNN). After applying the Convolutional Face Finder (CFF) (Garcia and Delakis, PAMI 2004) on gray-scale images we obtain face images that we further process with different models.Face alignment
Our Convolutional Face Aligner (CFA). Geometric transformations (translation, rotation and zoom) are iteratively estimated and applied to precisely find the correct face bounding box.
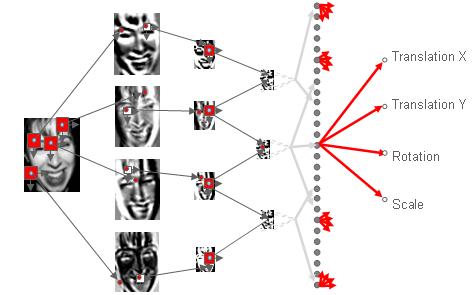
Some results of face alignment with CFA on an Internet dataset. For each image pair, on the left: the face bounding box detected by CFF (white) with the desired face bounding box (white); on the right: the face bounding box detected with CFA (in white)

Papers: VISAPP2008
Facial feature localisation
In this work, we estimate the location of four facial features: the eyes, the nose, and the mouth, in low-quality grey-scale images. As illustrated in the following diagram, we first extract normalised face patches found by the CFF, then our convolutional neural network highlights the positions of each of the four features in so-called feature maps, and finally, we project these positions back onto the original image.

Here are some results on difficult examples showing robustness of this method to extreme illumination, poor quality and contrast, head pose variation, and partial occlusions:

Papers: ISPA2005, CORESA2005 (best student paper), MLSP2007
Other work on facial image analysis on low-quality grey-scale images, e.g. face recognition, gender recognition, can be found here: IWAPR2007, PHD-THESIS2007
Object detection in images
We applied convolutional neural networks (CNN) to the task of object detection in still images. The models are "light-weight" but very robust to common types of noise and object/image variations.
Here are some results on cars and motorbikes:


Papers: VOCC2005
Some results on the difficult task of transparent logos detection (France 2 TV logo):

Papers: ICANN2006
Object segmentation in videos
We proposed a spatio-temporal segmentation of moving objects using active contours with non-parametric region descriptors based on dense motion vectors. Here are some examples of segmentations of single video frames.
| motion vectors for one video frame | motion magnitude | initial contour | intermediate contour | final result |
|---|---|---|---|---|
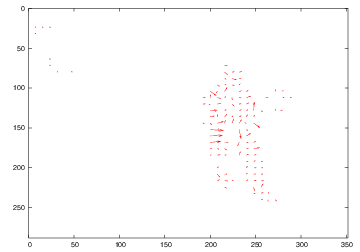 |
 |
 |
 |
 |
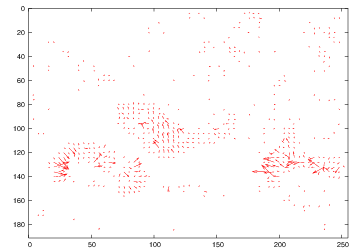 |
 |
 |
||
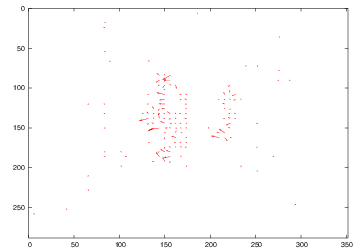 |
 |
 |
 |
Papers: GRETSI2005, JMIV2006, MASTER-THESIS2004